日本語・日本語教育を研究する 第39回 J-CAT(Japanese Computerized Adaptive Test)
日本語・日本語教育を研究する
このコーナーでは、これから研究を目指す海外の日本語の先生方のために、日本語学・日本語教育の研究について情報をおとどけしています。
筑波大学大学院人文社会系/留学生センター 今井新悟
1.J-CAT (Japanese Computerized Adaptive Test)とは
J-CAT (Japanese Computerized Adaptive Test) はインターネットを通じて、コンピュータを使い、日本語能力を測るテストです。いつでも、どこからでも、無料で利用できます。文字・語彙、聴解、文法、読解の4セクションからなります。四肢択一の問題形式で、各セクション100点満点、計400点満点です。試験終了直後に成績が算出され、表示されます。成績はPDFにしてダウンロードすることもできます。対象は国内外の日本語学習者です。個人受験の他に、大学でのプレースメントテストのように団体受験もできます。一般的な日本語能力を測定するためのものであり、「アカデミック・ジャパニース」や「ビジネス日本語」などのように特化したものではありません。J-CATは熟達度テスト(proficiency test)です。診断テストではないので、例えば、「自動詞と他動詞の使い分けができる/できない」、「簡単な自己紹介ができる/できない」などという個々の知識や運用能力を診断するものではありません。ですから、J-CATでは受験者(注1)に対して、個々の問題項目についてのフィードバックはしません。その代わり、一律(one-scale)の点数で日本語能力を示します。級別に分かれておらず、どの級を受験するかを決めておく必要はありません。自動的に受験者の日本語のレベルによって、異なったテストになります。この仕組みをアダプティブテスト(adaptive test)と言います。
2.アダプティブテストの仕組み
アダプティブテストでは、受験者がどの問題項目に正解あるいは不正解であったかにより、その受験者の能力を推定して、その能力を持った受験者に最も合った問題、つまり、難しすぎず、易しすぎず、ちょうどよい難しさの問題を出題します。
アダプティブテストの日本語訳は適応型テストです。「適応」というのは、普通は「日本の生活にもようやく適応した」などのように使われるのが普通ですが、テストの文脈では、それぞれの受験者の能力に合うように問題項目の難易度を調節するということを意味します。この原理を理解するのに最もよいメタファー(喩え)は視力検査です。

図1 視力検査表
視力検査では、(国によってバリエーションはありますが)文字やランドルト環と呼ばれる輪が使われます。この輪はどこか一部分が切れて開いているもので、大きさが異なります。検査者は、まず、大きい輪を指し、被検者が輪の切れ目を正しく答えたら、何段階か小さい輪を指します。それも見えるとさらに小さい輪に移ります。被検者が見えない(正しく答えられない)場合には、検査者は少し大きい輪に戻って、被検者に見えるぎりぎりの境界を探します。最終的に、見える範囲で最も小さい輪の横に書いてある数字を視力として判定します。
この、輪の横に書いてある数字が、テストの場合は困難度というものに相当します。アダプティブテストでは、視力検査と同じように、難易度が高い(難しい)問題項目と難易度が低い(易しい)問題項目を織り交ぜて出題することによって、その受験者がぎりぎり正解できる難易度を探ります。視力検査と同じように、受験者の解答の正誤により、次に出題すべき問題項目の難易度を決めて出題します。これら一連の作業を検査者に代わってコンピュータが行うのでcomputerized adaptive testと言う訳です。以下はアダプティブテストでの問題項目の遷移と推定能力値の変化のイメージ図です。×は不正解を表し、○は正解を表します。誤答した後にはやや易しい問題項目が出て、正答した後にはやや難しい問題項目がでます。誤差がだんだん小さくなって、難易度の変動が徐々に小さくなっていき、最終的な能力値に収束していきます。
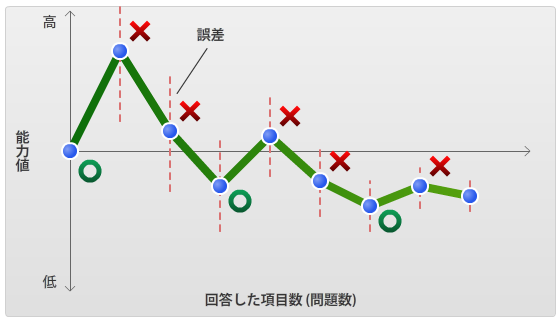
図2 アダプティブテストの問題項目選択遷移と能力値収束のイメージ
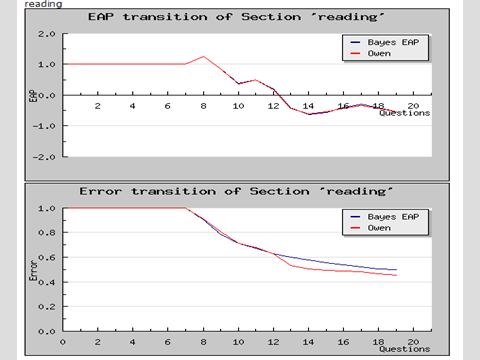
図3 実際の能力推定と誤差の収束の様子
問題項目は人が作りますが、一旦それがサーバー上の問題項目のデータの集まりであるアイテムプールというデータベースに入れば、あとは、コンピュータがそこから受験者ごとに適切な問題項目を選んで、インターネットを介してそれを受験者のコンピュータに送って、モニター画面に表示します。受験者は正答と判断した選択肢(注2)のボタンを選んでクリックします。その結果が再びインターネットを介してサーバーに送られます。その結果から、受験者の仮の能力値をコンピュータが項目応答理論(注3)に基づくアルゴリズムで計算して、その推定した能力値を持つ受験者に最も適切な難易度を持つ問題項目をアイテムプールから探し出します。それをまた、受験者のコンピュータに送ります。これを繰り返して、能力推定値が一定の誤差内に収まって安定したら、テストが終了し、能力値が確定します。相当数出題しても、何らかの理由によって誤差が基準よりも小さくならないときは、一定の出題数を超えたらテストを終了します。以上の一連の流れが自動的に進むので、テストの度に監督者がテスト問題を大量に印刷することも、解答用紙を回収することも、採点することも、採点ミスを犯すこともありません。
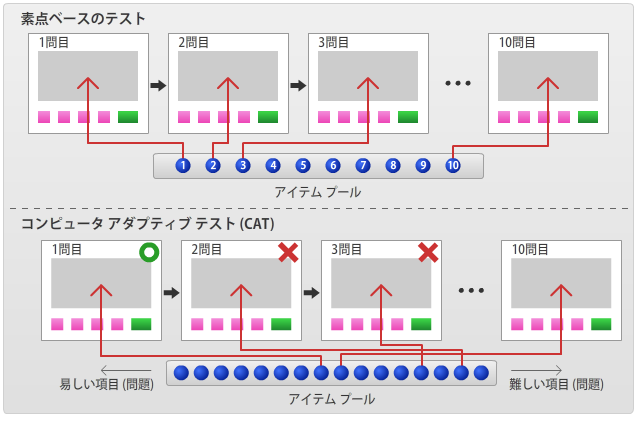
図4 順次出題される素点ベースのテストとアダプティブテストにおける問題項目選択方法のイメージ
3.アダプティブテストの利点
アダプティブテストであることにより、能力判定に無駄な問題は出題されなくなります。無駄な問題とは、受験者の能力から極端にかけ離れた難易度を持つ問題です。例えば、100問の問題が非常に簡単なものから非常に難しいものまで順序よく並んでいるテストを想像してください。そのテストを受験する者の能力が極めて高い場合、その受験者はほとんどの問題に難なく正解するでしょう。おそらくその受験者にとっては最後の数問に正解できるかどうかが能力判定に必要な情報であり、それ以外の問題はなくてもよく、それらに解答するのは時間の無駄です。無駄ではありますが、このテストの場合、解答しておかないと、不正解扱いになってしまうので、この受験者も一応はすべての問題に解答しなくてはなりません。一方で非常に能力の低い受験者は最初の数問は解けますが、そのあとの問題には手も足も出ないでしょう。しかし、このテストではおそらく時間制限があるので、その時間が来るまで、黙って待っていなくてはなりません。あるいは、試験監督者に白紙に近い解答用紙を提出して退出許可を求めるという、相当勇気のいることをしなくてはなりません。以上は、従来の紙のテストでは常に起こりうる状況です。これは、時間の無駄であり、精神的にも苦痛を伴います。
一方、アダプティブテストの場合は、そういう無駄を省くことができ、受験者に与える精神的負担も軽減されます。さらに、受験者の能力に近い、微妙な難易度の違いのある問題を集中的に出題することにより、従来のテストよりも短い時間で、より精度の高い判定ができます。
無駄と言えば、ペーパーテストで毎回破棄される大量の紙も大きな無駄です。紙を大量に処分するたびに心が痛みます。シュレッダーにかけた上でリサイクルできればまだいいほうで、その手間を惜しんで、焼却される場合も多いでしょう。そのような無駄がないJ-CATはエコなテストでもあるのです。
4.スタンダード・能力記述文との関連づけ
レベル設定とレベルごとに記述された能力記述文(Can-do statements)があれば、テストによって学習者のレベルを質的に示すことができます。テストの点数は量的です。これを解釈する質的な基準が必要です。日本語教師であれば誰でも、そして学習者の多くも、ナイーブな意味で、初級、中級、上級などというレベルのイメージを持っています。これを明文化しようというのが、CEFRやJFスタンダードであり、どのレベルであれば何ができるかを示すのが能力記述文です。CEFRの正式な名称は、"Common European Framework of Reference for Languages: Learning, Teaching, Assessment"です。これは学習、教育と並んで評価 (assessment)が大事であることを示しています。評価とその一部であるテストも、スタンダードや能力記述文と関連づけをするべきだというのが、CEFRの理念であることは明らかです。能力記述文とJ-CATの関連付けのための予備調査として、いくつかの能力記述文とJ-CATの得点の相関を調べてみました。相関の高いもの、低いものがあることが分りました。これは、能力記述文の中にはテストで測定する構成概念に合致しているものと合致していないものがあることを示しています。この結果を参考にして、今後、スタンダードおよび能力記述文とJ-CATとの関連付けを行う予定です。
J-CATのサイト
J-CAT
〔注釈〕
- 注1「受験者」は「受検者」と表記することもあります。
- 注2「選択肢」は「選択枝」と表記することもあります。
- 注3素点や偏差値を用いるのが古典的テスト理論です。古典的という名前ですが、平均点、標準得点など、普通のテストは古典的テスト理論を使っています。項目応答理論ではロジット得点というものを使います。これにより、古典的テスト理論では不可能な、問題項目の等化が可能になり、異なる受験者集団や異なるテストセットの影響を受けない、不変的な能力値が算出できます。これによって、いつ、誰が、どんなテストセットを受験しても、その得点の価値が変わることがありません。
参考文献
- 今井新悟・伊東祐郎・中村洋一・菊地賢一・赤木彌生・中園博美・本田明子 (2010)『J-CAT Japanese Computerized Adaptive Test-日本語能力をコンピュータで測る-』山口大学留学生センター
- 今井新悟 (2010)「J-CAT(Japanese computerized adaptive test)の得点とCan-doスコアの関連づけ」ヨーロッパ日本語教育第14回ヨーロッパ日本語教育シンポジウム報告・論文集Japanese Language Education in Europe 14,
The Proceedings of the 14th Japanese Language Symposium in Europe. pp.140-147.
- 事業内容を知るトップ
- 文化芸術交流[文化]
- 日本語教育[言語]
- 日本研究・国際対話[対話]
- JF digital collection
- 特別事業/周年事業等
- 顕彰事業
- 刊行物のご案内